Kontext Multi-Input Edit - ControlNets and More


Details
Download Files (1)
Model description
The purpose of this model is to allow for editing with multiple input images but only one output image. It works similar to Qwen Image Edit but for Kontext. It uses the keywords "image1" and "image2" to reference the inputs.
Here are some examples from the training data to help you understand prompting:
Example 1:
Inputs:
 Prompt:
Prompt:
Shift the man from image1 into the stance from image2: stand tall, feet hip‑width, hands clasped in front, head angled left, same neutral set lighting and beige athleisure outfit.Output:

Example 2:
Inputs:
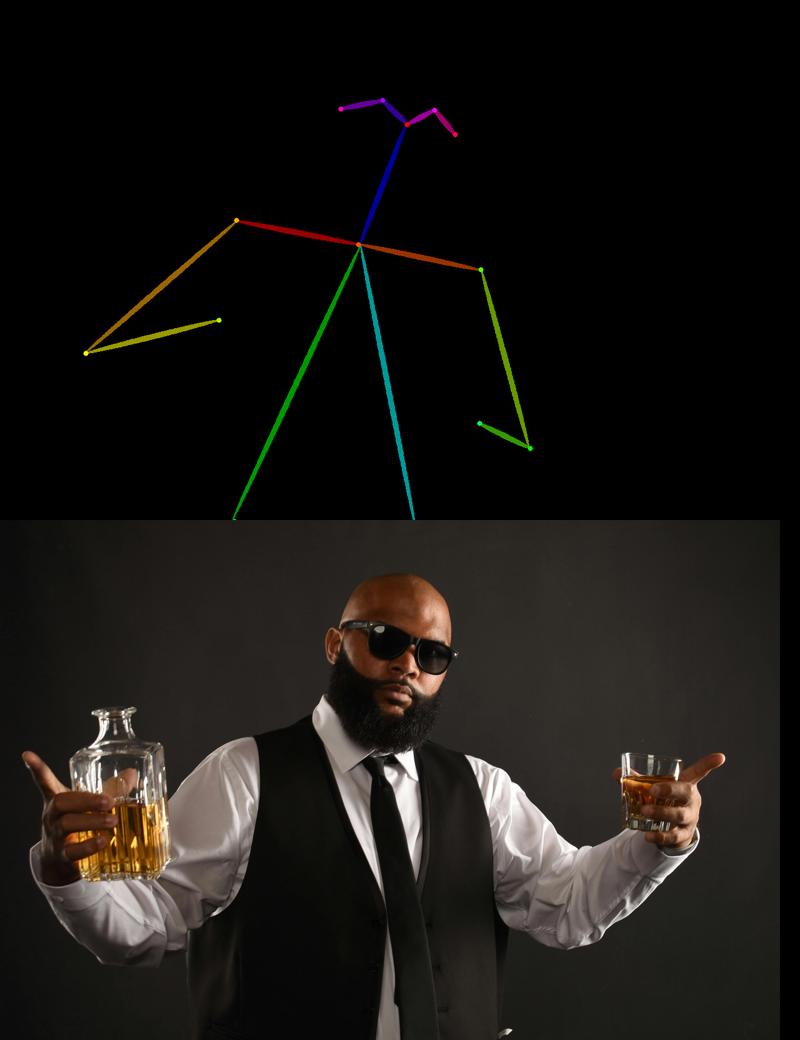 Prompt:
Prompt:
Move the man from image2 to the smooth, mid‑pour moment captured in the OpenPose from image1: crop waist‑up, angle his body a touch left, lift the square decanter above the glass so a golden stream flows, and let his gaze track the liquor with focused ease. Preserve his matte sunglasses, impeccably groomed beard, tailored black vest and tie, silver watch, rich whisky tones, and the moody, single‑direction studio light, producing a crisp portrait that blends his full‑arm flourish into this refined bartender action exactly as in the OpenPose from image1Output:

Example 3:
Inputs:
 Prompt:
Prompt:
image1 man in the cream-white suit and pink knit tie, same stone-wall setting, same lighting and framing, but adopt the joyful double-raised-hands pose shown in image2, palms open and level with his head, fingers spread, retaining his exact smile, outfit, background and color palette from image1Output:

Instructions:
The inputs should be stitched together for the input with them either side by side if they are vertical images, top and bottom if they are horizontal images. For square images it was trained to work either way.
Here is a screenshot of the workflow I use so you can see how to format the inputs:
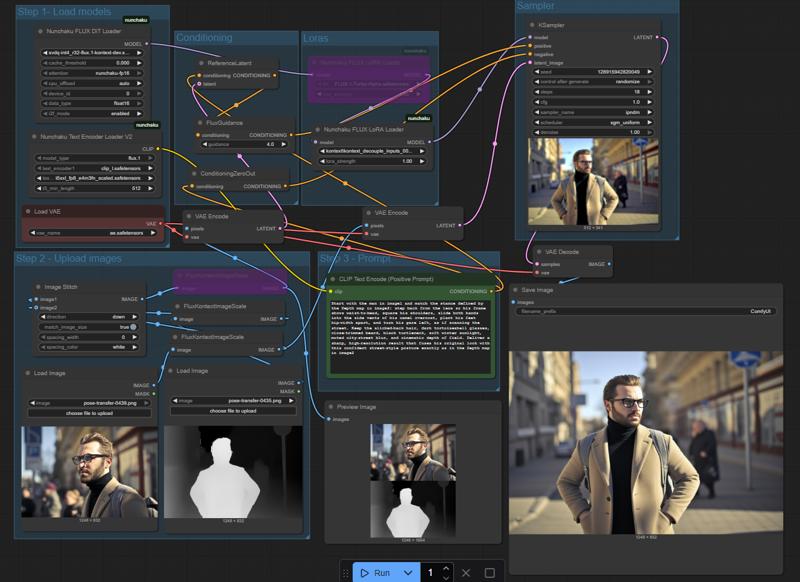
It has mostly been trained on people but it should handle a variety of subject matter. It was taught Canny, Depth, and OpenPose for Controlnets but it was also trained for editing between images without a controlnet, such as swapping characters, backgrounds, direct pose transfer, etc...
I have found that depth is working the best and OpenPose is generally working well but canny has been a little less successful which I intend to fix for later releases.
The lora is still a little undertrained and I'm working on a better dataset before I retrain with a higher step count but I would appreciate any feedback you have in the meantime.