Iori Yoshizuki ( DORA experiment version ) - I''s





















詳細
ファイルをダウンロード
モデル説明
新しいDORAタイプのLORAがリリースされたので、試してみることにしました。diag-OFT、IA3バージョン、LORAバージョン、またはLOCONバージョンと比較できます。これらすべては同じデータセットを使用しており、反復回数を調整して合計で約8エポックになるようにしています。訓練を終えようとした直前に停電が発生し、これが7エポックで終わってしまったという事実、信じられますか?とにかく、本題に入りましょう。
画像の品質としては、オリジナルのLOCONよりもわずかに良くなっていますが、特に印象的というほどではありません。LOCONがLORAに対してどのような関係かのように、このモデルはLOCONに対して同じ関係にあると言えるでしょう。
以下が私の利点と欠点の分析です:
利点:
LOCONよりもわずかに少ないステップで効果が出るようだ
LOCONよりもわずかに品質が良い
欠点:
訓練中にVRAMを大幅に消費し、私のGPUの8GB制限を超えたため、VRAM使用量を抑えるために勾配チェックポイントを有効化しなければならず、その結果、処理速度が遅くなった
勾配チェックポイントを使用すると、通常のLOCONと比較して1イテレーションあたりの処理時間が約2倍になる。つまり、訓練時間がほぼ2倍になる
結論:
VRAMに余裕があれば、これはLOCONの自然な進化ですが、残念ながら画期的なものではありません。
データセット、以前のエポック、訓練用TOMLファイルを追加します。注:以前のエポックを訓練データに添付し忘れていましたが、今では正しく含まれています。
(CivitAIはサンプル画像を縮小しているようです。ギャラリーで確認してください。)
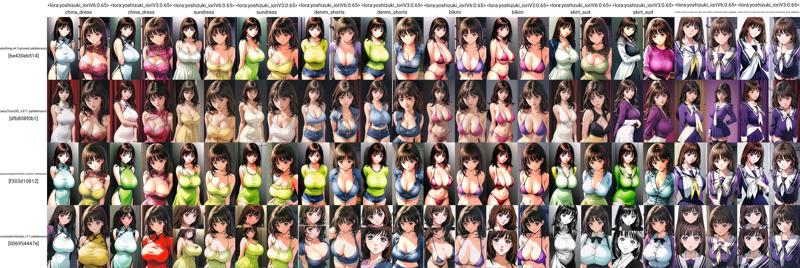
ちなみに、以下を使用して良い結果が得られました:lora:yoshizuki\_ioriV6:.65 yoshizuki_iori
タグ付けされた衣装は以下の1つだけです:
- school_uniform_purple_shirt_blue_skirt_white_neckerchief_black_thighhighs