Iori Yoshizuki ( DORA experiment version ) - I''s





















详情
下载文件 (2)
模型描述
I saw the new DORA type LORA has been released SO I had to try. You can compare against the diag-OFT, the IA3 version, the LORA version or the LOCON version. All of them use the same dataset only with changes in repetitions to keep them around 8 epochs total. Can you believe there was a damn black out minutes before i finished training so this ended up at epoch 7? Regardless lets go to the meat of the issue.
Image wise it looks slightly better than original LOCON, nothing impressive I'd say it is to LOCON what LOCON is to LORA.
Here's my analysis of pros and cons:
Pro:
Seems to require slightly less steps than LOCON
Slightly better quality than LOCON
Cons:
Uses way more VRAM in training pushing my card past the 8GB limit, So i had to activate Gradient checkpointing to keep VRAM usage down with the consequent slowdown.
Using Gradient checkpointing it takes about twice the amount per iteration than a normal LOCON. Essentially doubling training time.
Conclusion:
As long as you have the VRAM it is a natural evolution of LOCON, but sadly nothing revolutionary.
I will add the dataset, previous epochs, training TOML file. NOTE: I had forgotten to attach earlier epochs into the training data, They should be there now.
(civit seems to have downscaled the sample image, check in the gallery.)
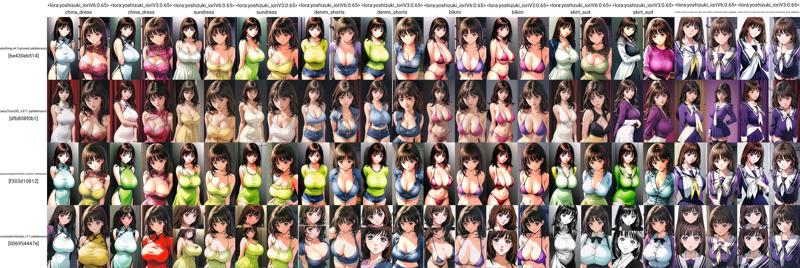
Btw got good results using: <lora:yoshizuki_ioriV6:.65> yoshizuki_iori,
The only tagged outfit is:
school_uniform_purple_shirt_blue_skirt_white_neckerchief_black_thighhighs