Regularization Image Workflow & Collection for FLUX



詳細
ファイルをダウンロード
このバージョンについて
モデル説明
FLUXモデルの作成を支援するためのリソース
FLUXに多くの人が参入するにつれ、一部のLoRAがモデルの他の要素に望ましくない影響を与えることが注目されるようになってきました。たとえば、男性と女性のキャラクターを正しく区別できなくなる、キャラクターの特徴が背景キャラクターに滲出してしまう、または特定のLoRAを使用すると異なるスタイルをプロンプトできなくなるなどです。
これはほぼ常にデータセットに正則化画像が不足していることが原因です!
FLUXは、トレーニングに使用されるデータセットによって元のトレーニングの要素を忘れやすいという特性を持っており、そのため正則化画像はStable Diffusionモデルよりもはるかに重要であり、データセットの20〜50%を占めるべきです。
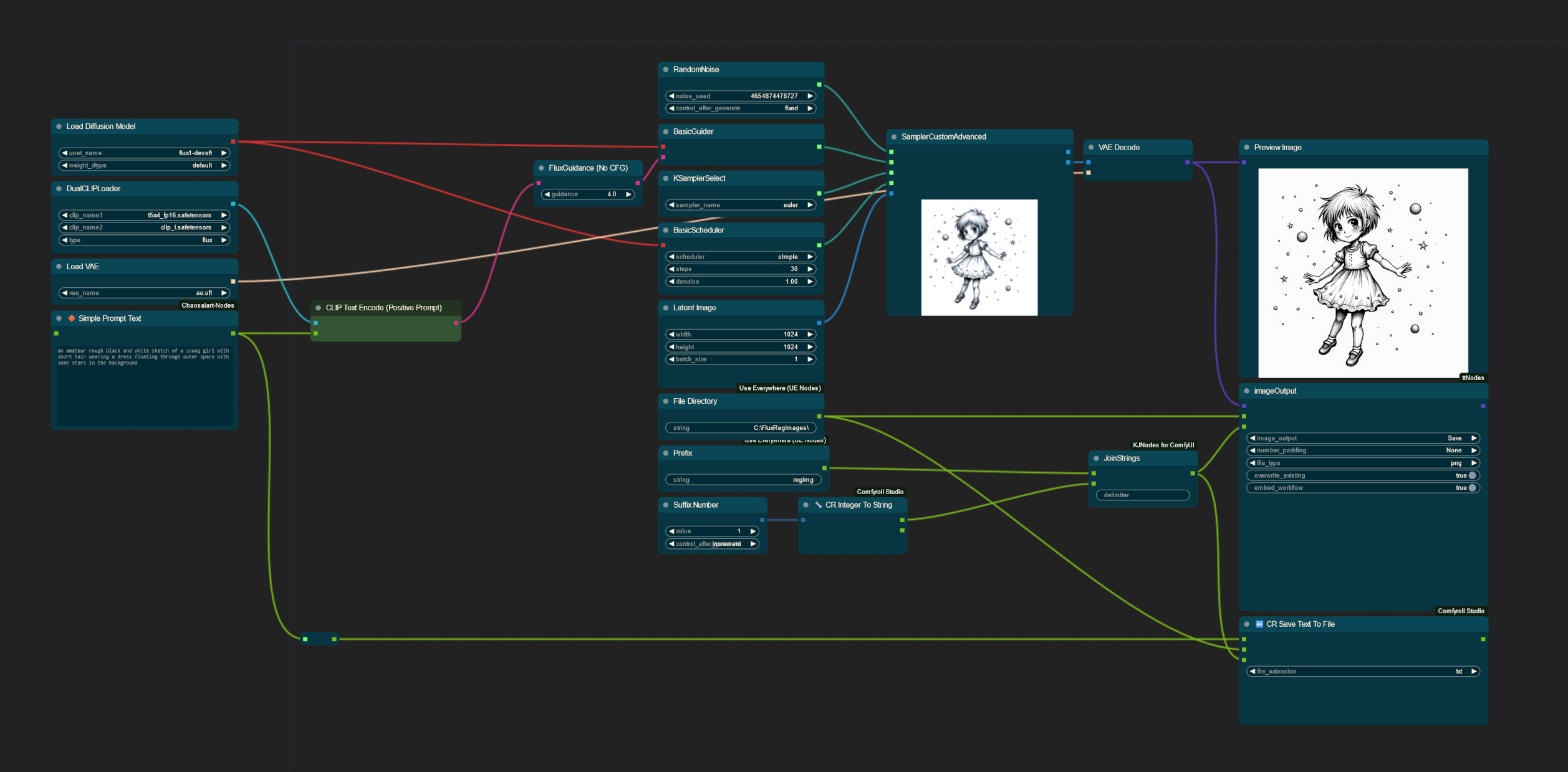
しかし、多くの人が正則化画像を避ける理由も十分に理解しています。大規模なデータセットに対する自然言語キャプション作成はすでに面倒であり、そこで私は以下のワークフローを開発しました!
このワークフローは以下の2つの重要な原則に基づいています:
正則化画像とその対応するキャプションは、元のモデルが生成するものにできるだけ近いものであるべきで、その重みを維持する必要があります。
既存の画像にキャプションを付けるよりも、画像を生成するためにプロンプトを入力する方がはるかに手間が少なく、現在の自動キャプション生成手法よりもはるかに信頼性が高いです。
この観点から、私のワークフローでは、ComfyUIを使用してFLUXで画像を生成し、それに付随するキャプションを含む.txtファイルを保存できます。現在のワークフローには含まれていませんが、FLUX用の自動プロンプターを使用してさらにプロセスを自動化することも可能です!また、すでに私が自分のデータセットで使用するために生成した、1024x1024サイズの正則化画像40枚を同梱しています(必要に応じてchaiNNerや他のプログラムで一括リサイズできます)。
正則化画像に関する注意事項:
上記の通り、正則化画像はデータセットの20〜50%を占めるべきです。
トレーニング対象のクラスのさまざまなタイプで構成されるべきです。
人物をトレーニングする場合、正則化画像には男女両方、さまざまな人種、年齢、髪の色、衣装、画像スタイル、ポーズなど、多様な人物が含まれるべきです。
トレーニング対象のクラスに直接関係しない要素(背景、装飾品など)も、正則化画像の10〜20%を占めるべきです。
トレーニング中は、モデルが過学習していないかを判断するために、対象を含まないサンプルプロンプトもいくつか含めるのがベストプラクティスです。