Regularization Image Workflow & Collection for FLUX


세부 정보
파일 다운로드 (1)
이 버전에 대해
모델 설명
Resource to help creators with making better FLUX models
With many getting into FLUX, people have started to notice that some LoRAs will impact other elements of the model in less than desirable ways; failure to differentiate between male and female characters, character elements bleeding into background characters, and completely losing the ability to prompt different styles when using particular LoRAs.
This is almost always the result of a lack of regularization images in a dataset!
Flux is particularly sensitive to forgetting elements of it's original training depending on the dataset used to train it, and thus regularization images are far more important than they were in Stable Diffusion models, and should make up between 20-50% of your dataset.
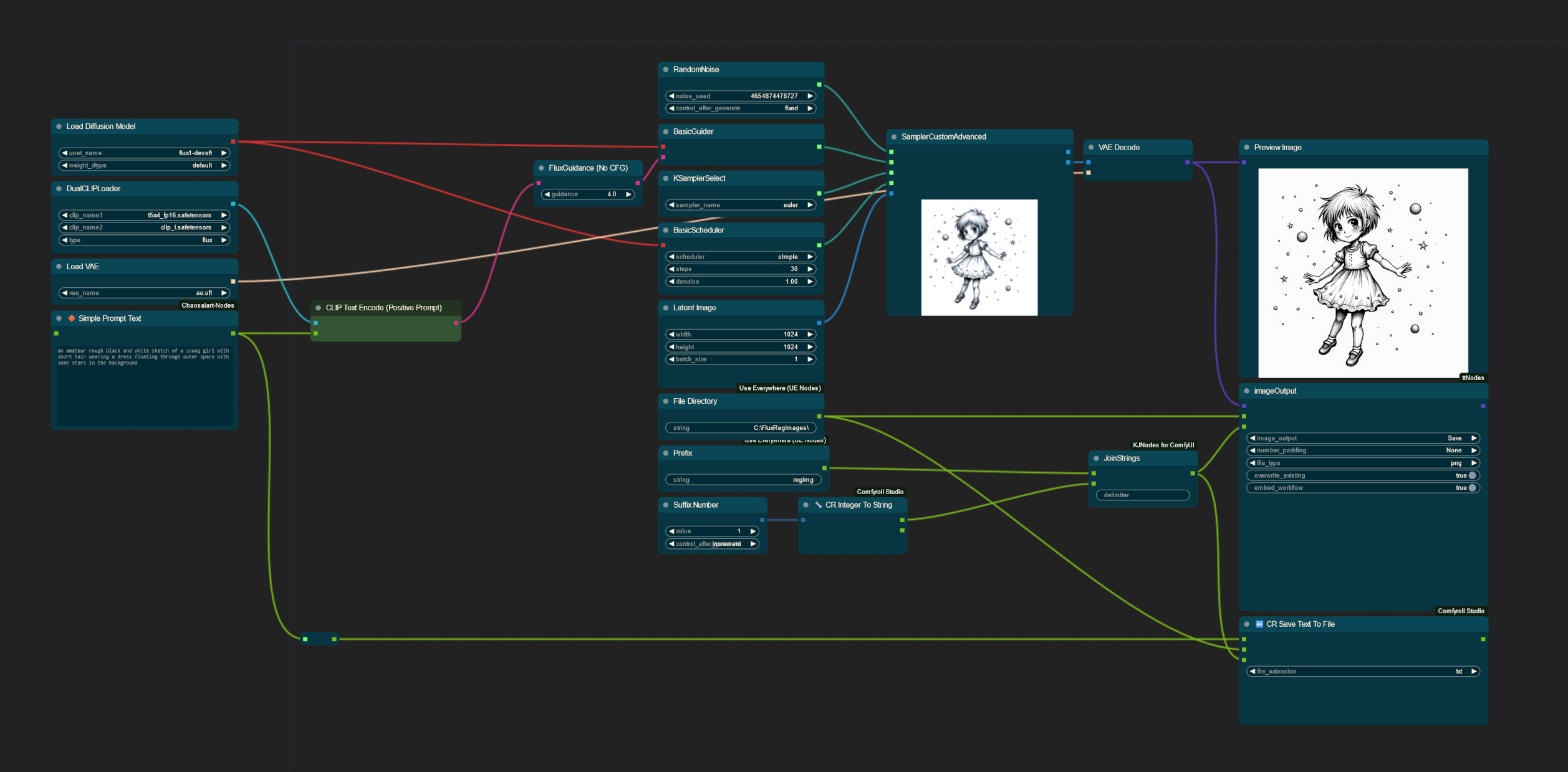
But I fully understand why regularization images have been avoided by many; natural language captioning is already annoying as is for large datasets, which is why I developed the following workflow!
The workflow is based on 2 key principles:
Regularization images and their corresponding captions should be as close to what the original model would generate as possible to preserve it's weights
It is far less tedious to prompt an image for generation than it is to caption an existing image, and far more reliable than current auto-captioning methods
With this in mind, my workflow will allow you to generate an image using Flux with ComfyUI, and then will save a corresponding .txt file containing the caption used alongside it. Whilst not included in the workflow as is, you could also using auto-prompters for Flux to further automate the process! It also includes 40 regularization images in 1024x1024 (can be bulk-resized using chaiNNer or other programs as needed) I have already generated for use in my own datasets to get you started.
Notes for Regularization Images:
As stated earlier, regularization images should make up 20-50% of your dataset
Should primarily consist of a variety of different types of the class you're training
For a person, regularization images should primarily consist of people of both sexes, various races, ages, hair colors, clothing, image styles, poses, etc
Elements not directly attributed to your image class should also make up a portion (10-20%) of your regularization images (setting, background elements, props, etc)
When training, it is best practice to include some sample prompts not containing your subject in order to judge whether your model is being overfit