ID Sign - Flux
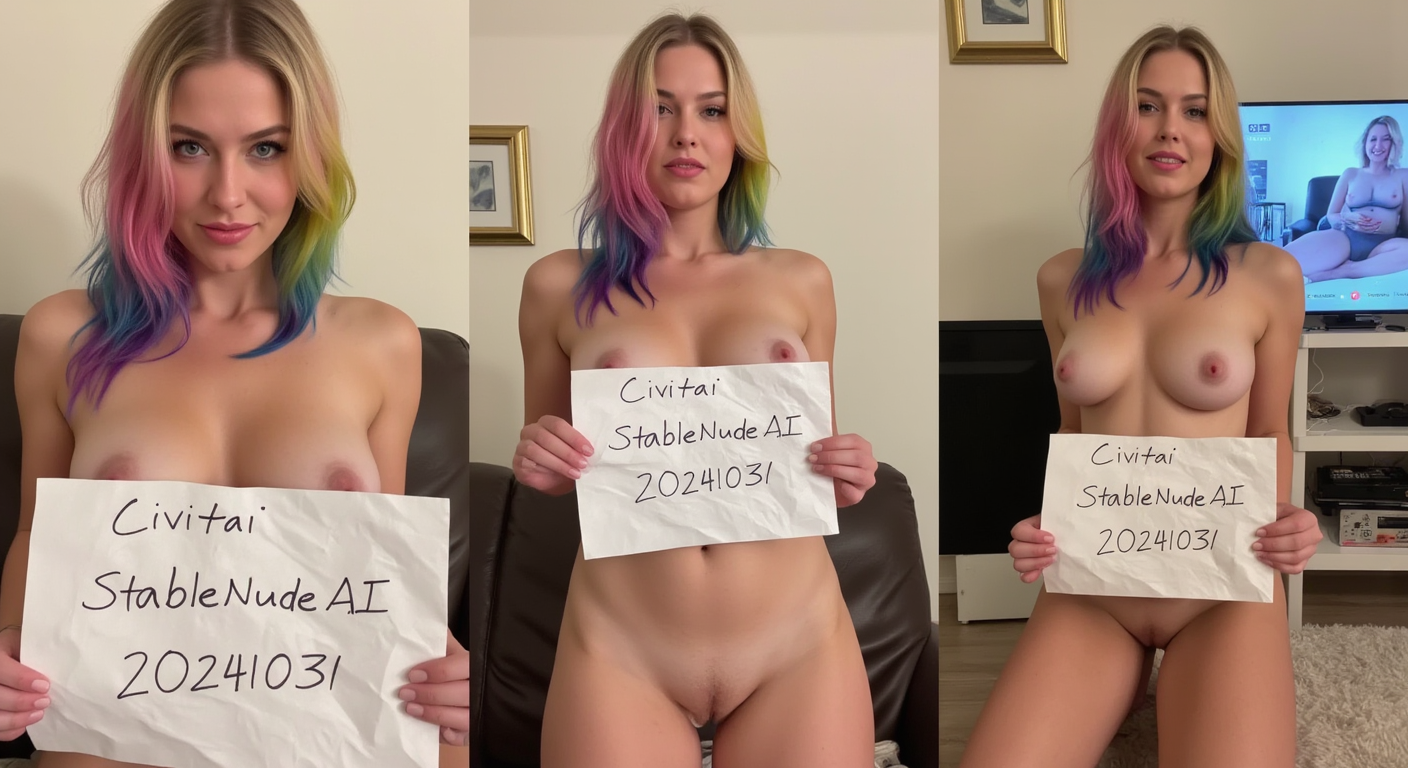









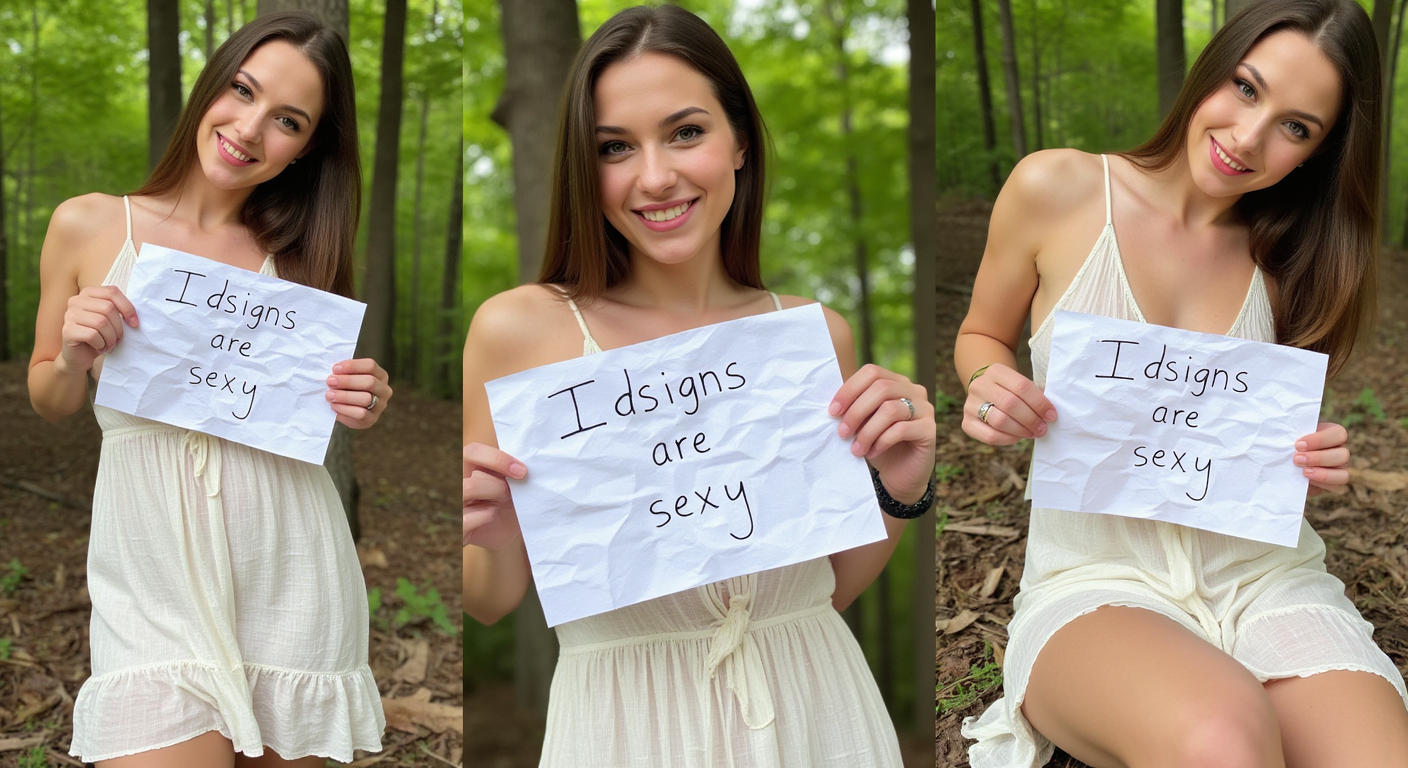






詳細
ファイルをダウンロード
モデル説明
これはIDサインの概念をモデリングした最初の試みではありません。初期の試みはSDXLで行われましたが、いずれも概念を十分に再現できませんでした。SDXL用の概念は単一の画像だけであり、フルパネルではありませんでした。OnOffを見た後、他のLoRAと非常にうまく組み合わせられることに気づき、もう一度試みる価値があると判断しました。この試みのプロンプトテキストはOnOffと似ており、効果が良かったため、これを模倣しました。
厳密に言えば、IDサインや検証サインとは、特定の情報が記されたしわくちゃの紙の一部を必要とします。さらに、画像が編集または変更されていないことを確認するために、このサインを複数の画像に表示する必要があります。3つのビューを同時に生成することで、画像間の一貫性を確保しました。特に、サインのテキストと紙のしわの整合性に注力しました。
このモデルはflux1-dev用のLoRAであり、flux1-devのチェックポイントで学習されました。オンラインで見つけた33枚の画像を用いて学習しました。画像は標準的な高さにリスケールされ、3枚ずつ合体して11枚のトレーニング用画像を作成しました。
トレーニング用のキャプションは以下の形式でした:
「3つのビューから見えた、しわくちゃの白紙のサインを握る女性、左の写真[SCENE]、中央の写真[SCENE]、右の写真[SCENE]」
ここで、SCENEは写真の簡潔な説明です。
SCENEの例:「裸で立っている」「サイドから見たパンツ姿で膝をつく」「裸で横たわっている」「サイドから見た裸」
推奨設定
このモデルは以下のように設定すると良好な結果を出します:
- ストレングス:1
- Distilled CFG:3-3.5
- ステップ数:30
- サンプラー:Euler Simple
- チェックポイント:fluxunchainedArtfulNSFW
- 解像度:1408x768
プロンプティング
以下のプロンプト形式で良好な結果が得られました。
「3つのビューから見えた、しわくちゃの白紙のサインを握る女性、サインには("TEXT":1.3)と書かれている。すべての写真に共通する要素を記述する。左の写真 SCENE_1、中央の写真 SCENE_2、右の写真 SCENE_3 lora:idsign_flux_v1:1」
全体のシーンは画像の共通要素でプロンプトできます。たとえば、「茶色の髪の女性が寝室にいる」「ビーチで」「大きな胸を持つドレスを着た女性」のように、完全な文でプロンプト可能です。
個々のシーンもプロンプトできます。短いプロンプトのほうがサインの整合性が高まりました。たとえば、「ベッドに横たわる」「椅子に座る」「外で立つ」
他のプロンプティング方法でも動作する可能性があります。
強み
- 正しいテキストを持つIDサインを生成する
- テキストとしわが一貫したIDサインを生成する
- 各写真を個別にプロンプト可能
- 多種多様な被写体で動作する
- 3つ以上のビューを生成可能(トレーニングデータには含まれていないが、fluxに感謝)
弱み
- 画像の一貫性は2~10%の確率でしか発生しない(プロンプトに非常に依存)
- 単純でない角度で持たれたサインは動作しない
- 画像は完全に一貫していない
バージョン2
より小さなLoRAサイズを試みましたが、効果は劣りました。より多様なトレーニング画像セットがあれば、モデルの性能は向上するでしょう。別のバージョンが作成される可能性があります。