LTX IMAGE to VIDEO with STG, CAPTION & CLIP EXTEND workflow

세부 정보
파일 다운로드 (1)
이 버전에 대해
모델 설명
NEW LTX-2 Workflows here: https://civitai.com/models/2318870
Workflow: Image -> Autocaption (Prompt) -> LTX Image to Video
LTX Prompt Enhancer (LTXPE) might have issues with latest Comfy and Lightricks update
Update July 20th 2025: GGUF Models for LTX 0.9.8:
Distilled model, works with V9.5: https://huggingface.co/QuantStack/LTXV-13B-0.9.8-distilled-GGUF/tree/main
Dev model, works with V9.0: https://huggingface.co/QuantStack/LTXV-13B-0.9.8-dev-GGUF/tree/main
(see "Model Card" in above links for LTX 0.9.8 VAE and textencoder downloads)
V9.5: LTX 0.9.7 Distilled Workflow supporting LTX 0.9.7 Distilled GGUF Model.
There is a workflow with Florence and another one with LTX Prompt Enhancer (LTXPE)
GGUF Model can be downloaded here:
https://huggingface.co/wsbagnsv1/ltxv-13b-0.9.7-distilled-GGUF/tree/main
VAE and Textencoder are identical to previous LTX 0.9.6 model (see V8.0 below)
LTX 0.9.7 Distilled is using only 8 steps and is very fast.
V9.0: LTX 0.9.7 Workflow supporting LTX 0.9.7 GGUF Model.
There is a workflow with Florence and another one with LTX Prompt Enhancer (LTXPE)
GGUF Model can be downloaded here:
https://huggingface.co/wsbagnsv1/ltxv-13b-0.9.7-dev-GGUF/tree/main
VAE and Textencoder are identical to previous LTX 0.9.6 model (see V8.0 below)
LTX 0.9.7 is a 13billion parameter model, previous versions only had 2b parameters, therefore it is more heavy on Vram usage and requires longer process time. Try V8.0 below with model 0.9.6 or V9.5 for very fast rendering.
V8.0: LTX 0.9.6 Workflow (dev and distilled GGUF model in same workflow)
there is a version with Florence2 Caption and a version with LTX Prompt Enhancer (LTXPE)
GGUF Models (Dev & Distilled) can be downloaded here:
https://huggingface.co/calcuis/ltxv0.9.6-gguf/tree/main
vae: pig_video_enhanced_vae_fp32-f16.gguf
Textencoder: t5xxl_fp32-q4_0.gguf
V7.0: LTX 0.9.5 Model Version GGUF with Wavespeed/Teacache.
LTX 0.9.5 GGUF Model and VAE: https://huggingface.co/calcuis/ltxv-gguf/tree/main
(vae_ltxv0.9.5_fp8_e4m3fn.safetensors)
Clip Textencoder: https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
There are 2 worklfows, a main workflow with florence caption only and additional one with florence and LTX prompt enhancer. Setup with Wavespeed (bypassed by default, Strg+B to activate)
workflow works with all GGUF models: 0.9 / 0.9.1 / 0.9.5
uncensored LLM for Prompt enhancer: https://huggingface.co/skshmjn/unsloth_llama-3.2-3B-instruct-uncenssored
-Outdated (march 2025)- V6.0: GGUF/TiledVAE Version & Masked Motion Blur Version
Updated the workflow with GGUF Models, which save Vram and run faster.
There is a Standard Version, which uses just the GGUF Models and a GGUF+TiledVae+Clear Vram Version, that reduces Vram requirements even further. Tested the larger GGUF model (Q8) with resolution of 1024, 161 frames and 32 steps , the GGUF Version peaked Vram usage at 14gb, while the TiledVae+ClearVram Version peaked at 7gb. Smaller GGUF Models might reduce requirements further.
GGUF Model, VAE and Textencoder can be downloaded here:
(Model&VAE): https://huggingface.co/calcuis/ltxv-gguf/tree/main
(anti Checkerboard Vae): https://huggingface.co/spacepxl/ltx-video-0.9-vae-finetune/tree/main
(Clip Textencoder): https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
You can go for the GGUF Version with 16gb+ and the TiledVae+ClearVram with less than 16gb Vram.
Masked Motion Blur Version: Since LTX is prone to motion blur, added an extra group to the workflow which allows to set a mask on input image, apply motion blur to mask, to trigger specific motion. (sounds better than it actually works, useful tho in some cases). GGUF and GGUF+TiledVAE+ClearVram version included.
V5.0: Support for new LTX Model 0.9.1.
included an additional workflow for LowVram (Clears Vram before VAE)
added a workflow to compare LTX Model 0.9.1 vs LTX Model 0.9
(V4 did not work with 0.9.1 when the model was released (hence v5 was created), this has changed as comfy & nodes were updated in the meantime, now you can use both Models (0.9 & 0.9.1) with V4, also with V5. Both have different custom nodes to manage the model, other than that, both versions are the same. If you run into memory issues/long process time, see tips at the end)
-Outdated (march 2025)- V4.0: Introducing Video/Clip extension :
Extend a clip based on last frame from previous clip. You can extend a clip about 2-3 times before quality starts to degenerate, see more details in the notes of the worflow.
Added a feature to use your own prompt and bypass florence caption.
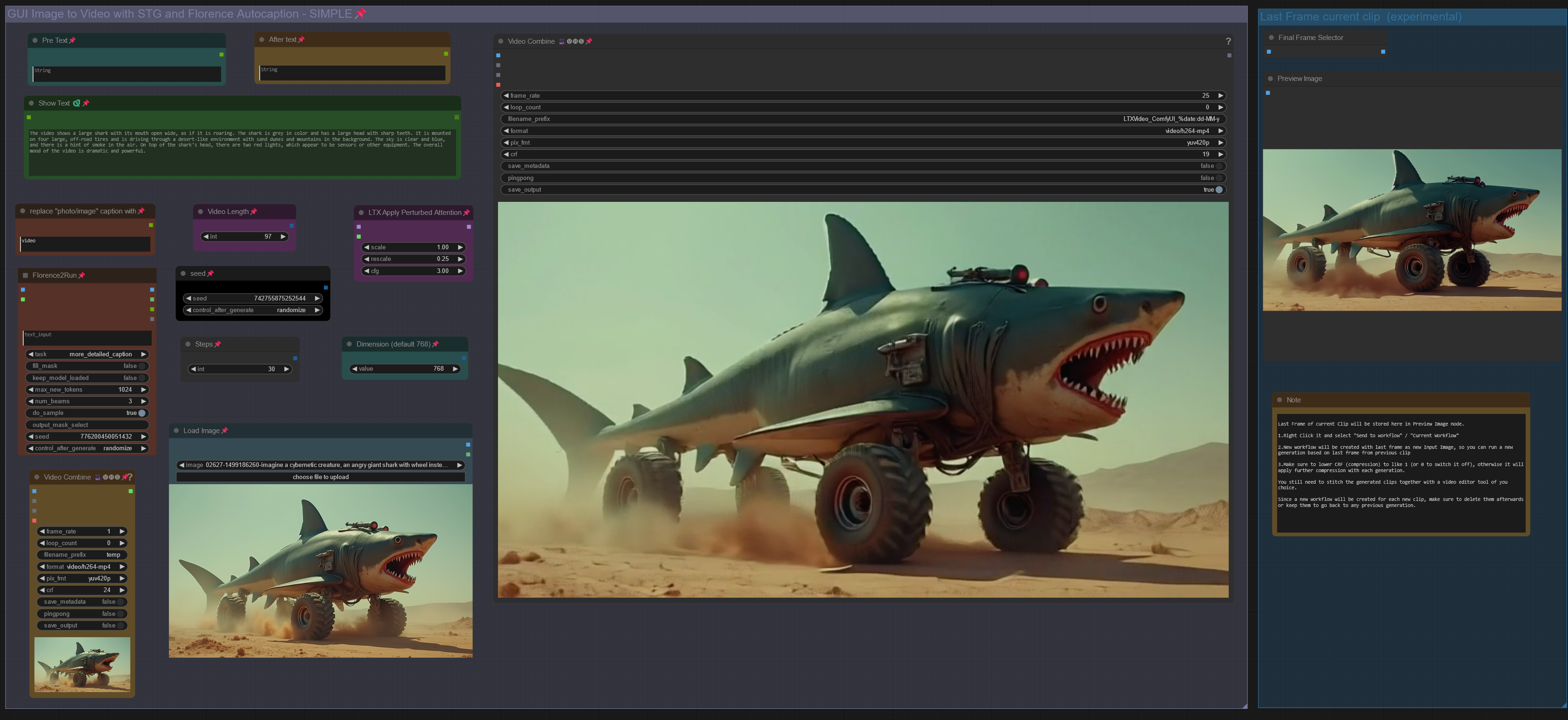
V3.0: Introducing STG (Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling).
Included a SIMPLE and an ENHANCED workflow. Enhanced Version has additional features to upscale the Input Image, that can help in some cases. Recommend to use the SIMPLE Version.
replaced the height/width Node with a "Dimension" node that drives the Videosize (default = 768. increase to 1024 will improve resolution, but might reduce motion, also uses more VRAM and time). Unlike previous Versions, Image will not be cropped.
Included new node "LTX Apply Perturbed Attention" representing the STG settings (for more details on values/limits see the note within the workflow) .
Enhanced Version has an additional switch to upscale Input Image (true) or not (false). Plus a scale value (use 1 or 2) to define the size of the image before being injected, which can work a bit like supersampling. As said, not required in most cases.
Pro Tip: Beside using the CRF value at around 24 to drive movement, increase the frame rate in the yellow Video Combine node from 1 to 4+ to trigger further motion when outcome is too static.
Node "Modify LTX Model" will change the model within a session, if you switch to another worklfow, make sure to hit "Free model and node cache" in comfyui to avoid interferences. If you bypass this node (strg-B) , you can do Text2Video.
V2.0 ComfyUI Workflow for Image-to-Video with Florence2 Autocaption (v2.0)
This updated workflow integrates Florence2 for autocaptioning, replacing BLIP from version 1.0, and includes improved controls for tailoring prompts towards video-specific outputs.
New Features in v2.0
Florence2 Node Integration
Caption Customization
A new text node allows replacing terms like "photo" or "image" in captions with "video" to align prompts more closely with video generation.
V1.0: Enhanced Motion with Compression
To mitigate "no-motion" artifacts in the LTX Video model:
Pass input images through FFmpeg using H.264 compression with a CRF of 20–30.
This step introduces subtle artifacts, helping the model latch onto the input as video-like content.
CRF values can be adjusted in the yellow "Video Combine" node (lower-left GUI).
Higher values (25–30) increase motion effects; lower values (~20) retain more visual fidelity.
Autocaption Enhancement
Text nodes for Pre-Text and After-Text allow manual additions to captions.
Use these to describe desired effects, such as camera movements.
Adjustable Input Settings
Width/Height & Scale: Define image resolution for the sampler (e.g., 768×512). A scale factor of 2 enables supersampling for higher-quality outputs. Use a scale value of 1 or 2. (changed to dimension node in V3)
Pro Tips
Motion Optimization: If outputs feel static, incrementally increase the CRF & frame rate value or adjust Pre-/After-Text nodes to emphasize motion-related prompts.
Fine-Tuning Captions: Experiment with Florence2’s caption detail levels for nuanced video prompts.
If you run into memory issues (OOM or extreme process time) try the following:
use the LowVram version of V5
use a GGUF Version
press "free model and node cache" in comfyui
set starting arguments for comfyui to --lowvram --disable-smart-memory
see the file in your comfyui folder: "run_nvidia_gpu.bat" edit the line: python.exe -s ComfyUI\main.py --lowvram --disable-smart-memory
switch off hardware acceleration in your browser
Credits go to Lightricks for their incredible model and nodes: