Hunyuan Video T2V With 3 LoRA(s) - (With 2 Phases Upscale and Frame Interpolation)

詳細
ファイルをダウンロード
このバージョンについて
モデル説明
これはHunyuanテキストから動画(T2V)のワークフローです。実際には新しいものではなく、別のワークフローのシンプルなバージョンです。
これは@iljoeが作成した「Hunyuan動画T2V with Face Detailer POC」のシンプルなバージョンであり、サンプリング原理は@LatentDreamによるものです。ぜひチェックしてください!
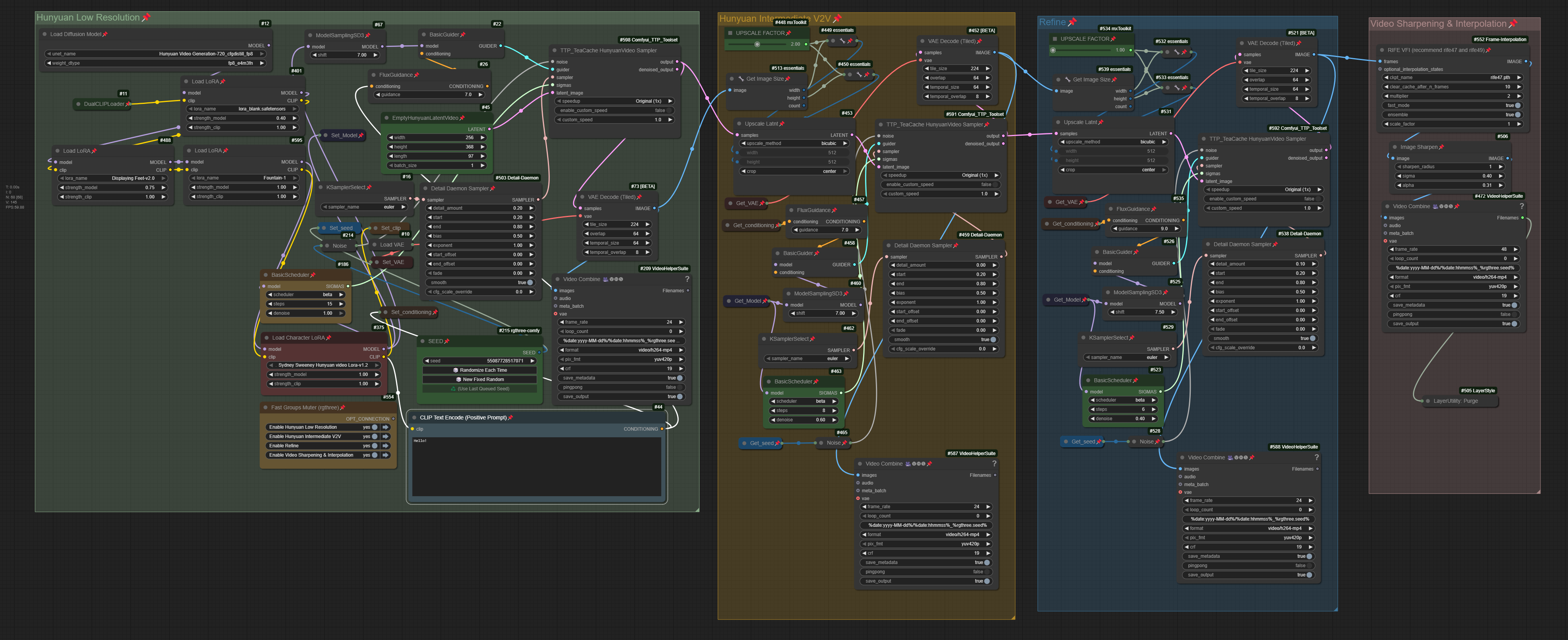
主なノード:
このノードは、フルモードに入る前に、適切な動画を検索するために使用します。最初の1つだけを選択し、他のものは無効にしてください。
最大3つのLoRAを設定できます。...でも、それ以上必要になる人はいるでしょうか?
こちらでシードを管理できます:
はい、わかります。これは古風なサンプラーです。TTP_teacacheサンプラーに置き換えることもできます。でも、もし手元にない場合は、そのまま古風なまま使うのが最善の方法かもしれません :)
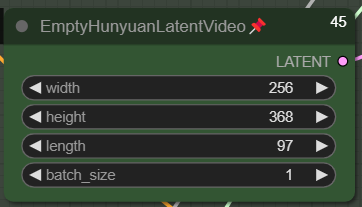
こちらで動画の解像度を設定してください。これは低解像度用の初期動画の設定です。長さは97フレーム、24fpsで4秒の動画です。より高い初期解像度を設定することも可能です。利点は、初期動画の解剖学的正確性(アナトミーの整合性)が向上する可能性があることです。ただし、欠点は明らかです:生成に時間がかかります。
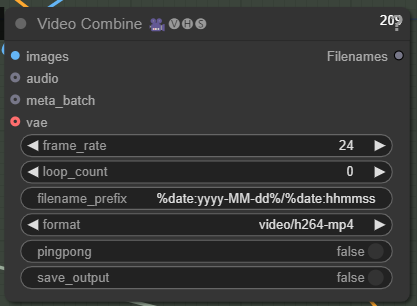
こちらでFPSを変更してください:
動画が「焦げた」または「ピクセル化」したように見える場合は、ノイズ除去量、ModelSamplingSD3、ステップ数を調整してください。@LatentDreamの記事を読んでください:TIPS: 💥 Hunyuan 💥 あなたが今、眠らしている爆弾。
フィードバックをお待ちしています!
Cheers!
このモデルで生成された画像
画像が見つかりません。