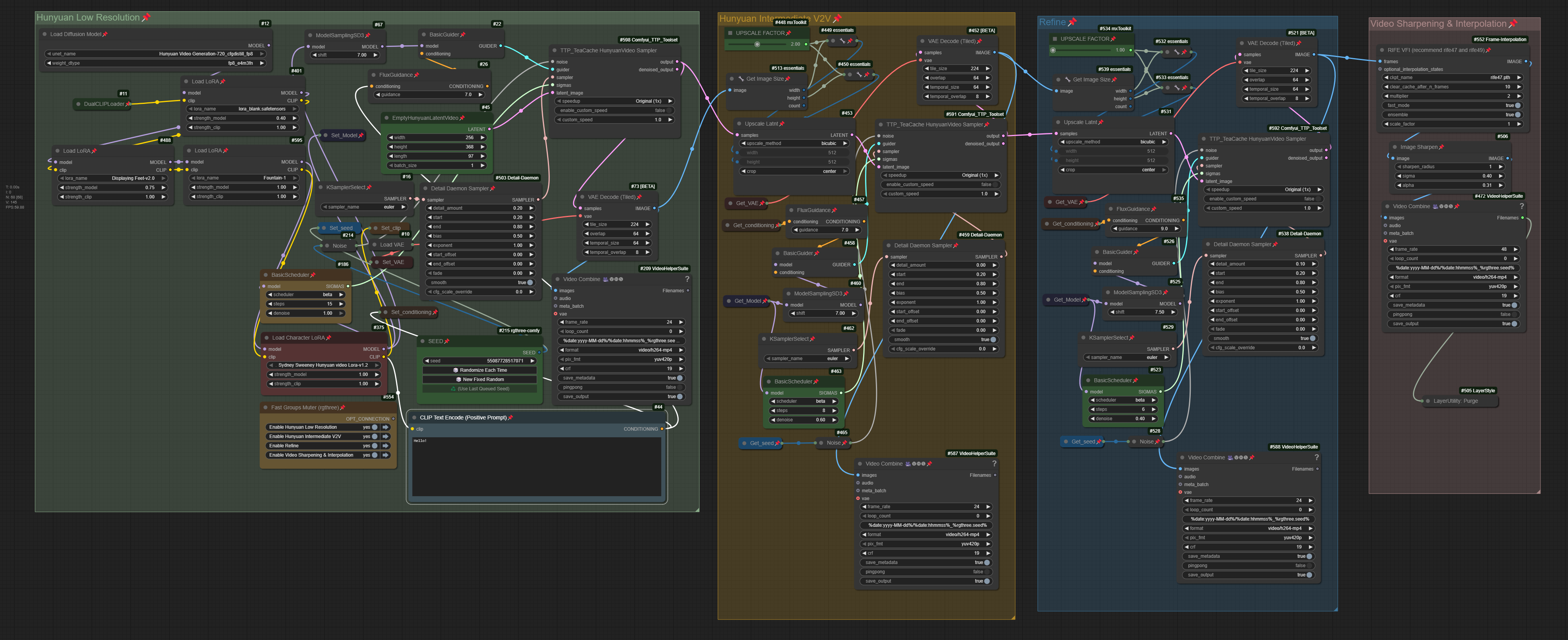
Hunyuan Video T2V With 3 LoRA(s) - (With 2 Phases Upscale and Frame Interpolation)

세부 정보
파일 다운로드 (1)
이 버전에 대해
모델 설명
This is a workflow of Hunyuan Text-to-Video (T2V). Actually, it is not new, but a simpler version of another workflow.
This is actually the simpler version of "Hunyuan video t2v with face detailer POC" by @iljoe, and the sampling principle by @LatentDream. go check them!
The Key-Nodes:
This node is for searching for the right video to be processed further, before full mode. Just select the first one and turn off the others.
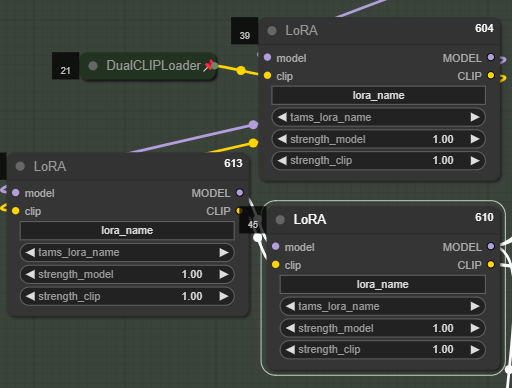
You can set up to 3 LoRA(s), or... who needs more tho?
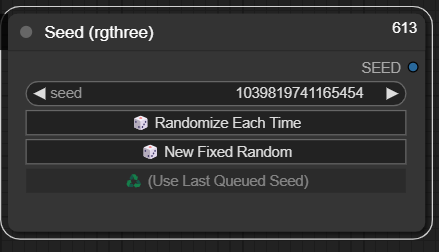
You can manage your seed here:
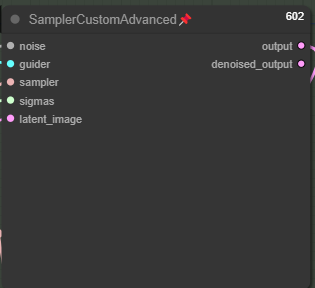
Yes, I know. This is an old-fashioned sampler. You can replace it with TTP_teacache Sampler. But if you don't have it, sometimes keeping it old-fashioned is the best way :)
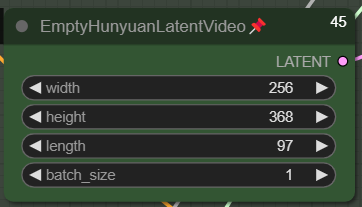
Set your Video dimension here. This is my setup of the initial video for Low Res. The length is 97 frames, it is a 24fps/4s video. You can set a higher initial dimension. The + is that the initial video would probably be better in anatomy (anatomy correctness), but the con is obvious: it takes longer to generate.
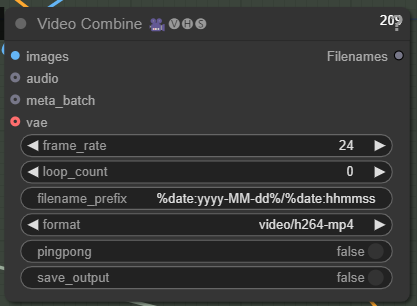
 Change your FPS here:
Change your FPS here:
Tweak the denoise, ModelSamplingSD3, and Steps if you encounter a "fried or pixelated" video. Read the article of @LatentDream : TIPS: 💥 Hunyuan 💥 the bomb you are sleeping on rn.
Feedbacks are appreciated!
Cheers!