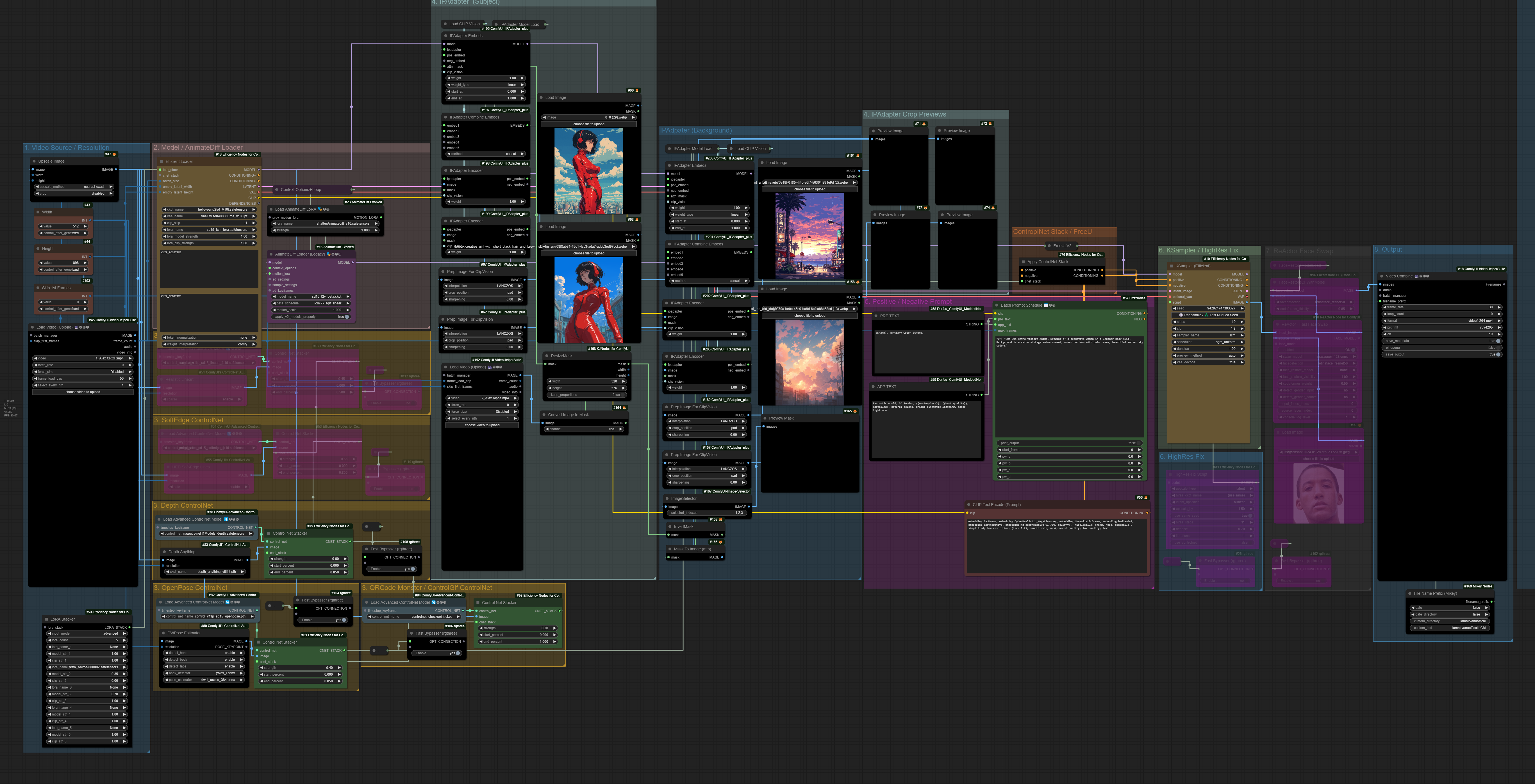
JBOOGX & THE MACHINE LEARNER'S ANIMATELCM SUBJECT & BACKGROUND ISOLATION via INVERTMASK VID2VID + HIGHRESFIX

세부 정보
파일 다운로드 (1)
이 버전에 대해
모델 설명
This is an evolution of my AnimateLCM workflow. Cut down and put together for ease of use.
This workflow should at MOST require 12-14GB of VRAM making it a lot more approachable for folks with smaller GPUs.
This workflow utilizes and requires an Alpha Mask that matches your video input to work properly. It will take the mask, resize is (shoutout to @Kijai for helping me get passed the initial CUDA errors), and invert it.
I recommend using MACHINEDELUSION'S PhotonLCM model with this workflow
How you go about getting that AlphaMask is entirely up to you. I personally like rotoscoping manually in Adobe After Effects for precision.
The first two IPAdapter images will be for your subject (the white part of your alpha mask).
The second two IPAdapter images will be for your background (the mask is being automatically inverted to reverse this).
Running the HighResFix at Bilinear will keep you from getting a CUDA on longer frame videos. At 1.5 you will get a clean 768x1344 output after the HighResFix is finished.
Appreciate everyone and all the support I receive.
Special shoutout to @cerspense @Purz @jeru @Fill @MidJourney.Man @PatchesFlows for allowing me to babble about my AnimateDiff wants and desires and helping me navigate how to get there when I hit a wall and hit it often.
Find me on IG @jboogx.creative