CogVideoX-v1.5-5B I2V workflow for lazy people (Including low VRAM)

详情
下载文件 (1)
模型描述
Update the Florence version:Many people encounter dependency errors when using the Joy Caption plugin. I use Florence as a replacement—it’s easier for beginners to avoid these issues.
Not an upgraded version of the previous one.
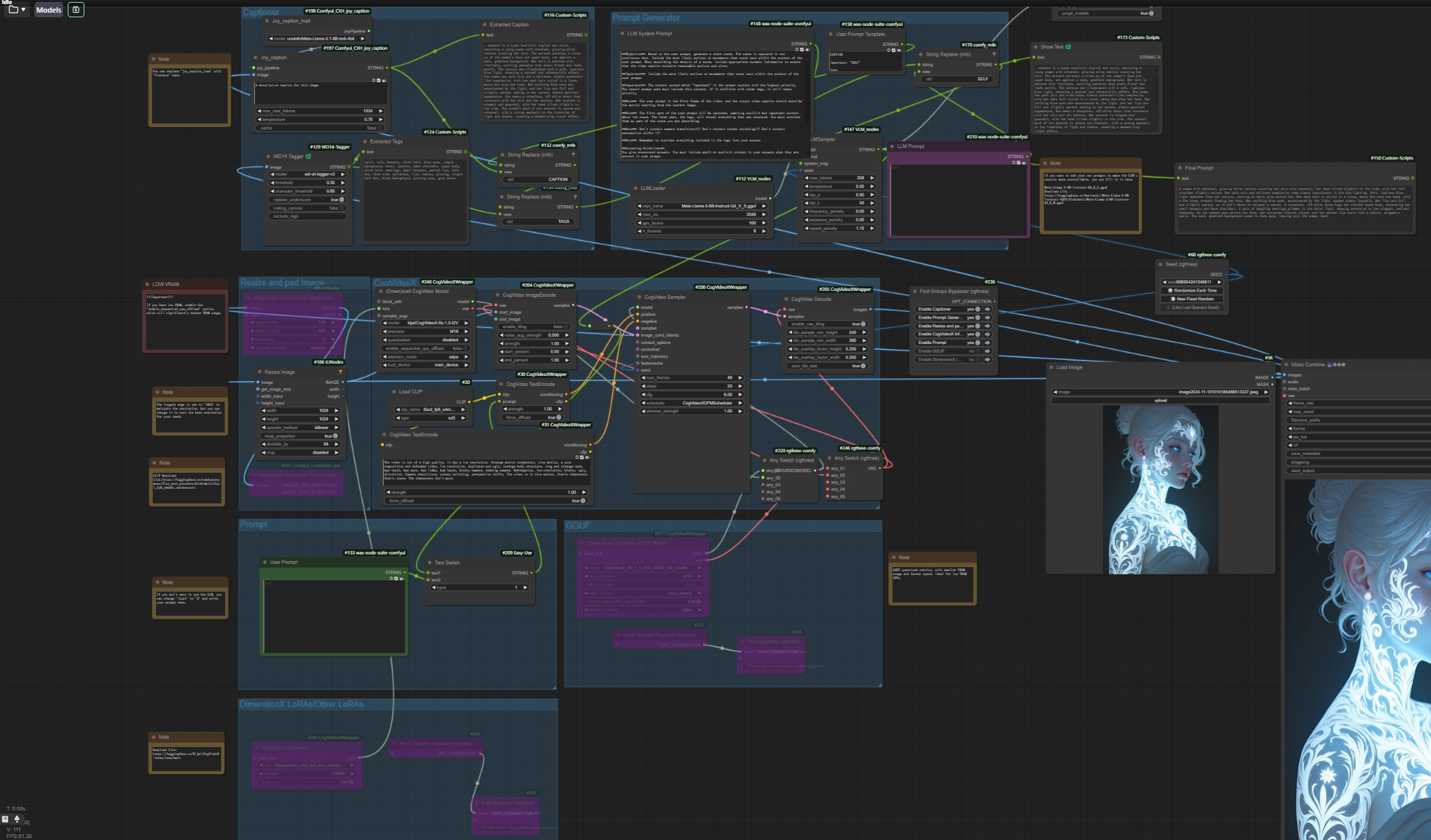
By using an LLM to write prompts for CogVideoX-v1.5-5B I2V, it helps those who don't know how to write prompts or are too lazy to do so make better use of CogVideoX v1.5. It also allows users to choose to add guiding prompts or turn off the LLM feature and write prompts entirely on their own.
Although the v1.5 version supports any resolution, there are still differences in quality depending on the resolution. You can test multiple resolutions to find the best one.
For low VRAM users, please keep the following features enabled.
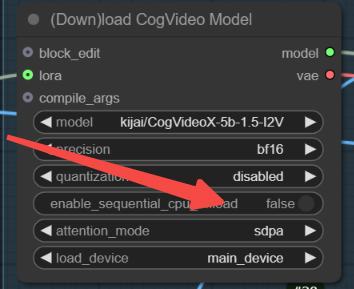
The GGUF version doesn't perform that well based on my tests, but v1.5 is still being updated, so we can expect better results in future versions.
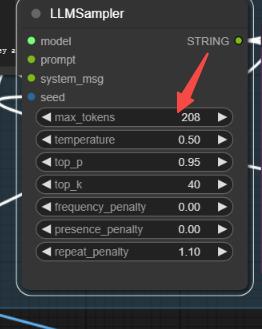
If this happens, it's because the LLM prompt is too long. You can change the random seed to regenerate, or modify the values below to reduce the tokens.